










12 recomendaciones para la implementación de automatización y orquestación de servicios


Rolando Barajas Moreno, PMP®

Empresas de diferentes industrias han adoptado modelos de automatización y orquestación de servicios para impulsar la modernización digital. Desde la optimización de campañas publicitarias dirigidas hasta la automatización de programas de mantenimiento predictivo, las plataformas de orquestación de flujos de trabajo como Control-M están desempeñando un papel fundamental para ayudar a las empresas a brindar mejores experiencias a sus clientes.
Las plataformas para automatización y orquestación de servicios (SOAP, por sus siglas en inglés) garantizan que los flujos de aplicaciones y datos se lleven a cabo en la secuencia y el momento correcto para garantizar la entrega exitosa de un servicio de negocio.
Si su empresa está lista para comenzar su viaje de automatización y orquestación de servicios, aquí hay 12 buenas prácticas que puede seguir:
- Soportar una visión “as-code”
Independientemente de si los flujos de automatización se crean a través de alguna interfaz gráfica o se escriben directamente en código, el control de versiones es obligatorio. Por supuesto, para habilitar un modelo de implementación moderno, su plataforma debe permitirle almacenar y administrar flujos de trabajo en algún formato de texto o código.
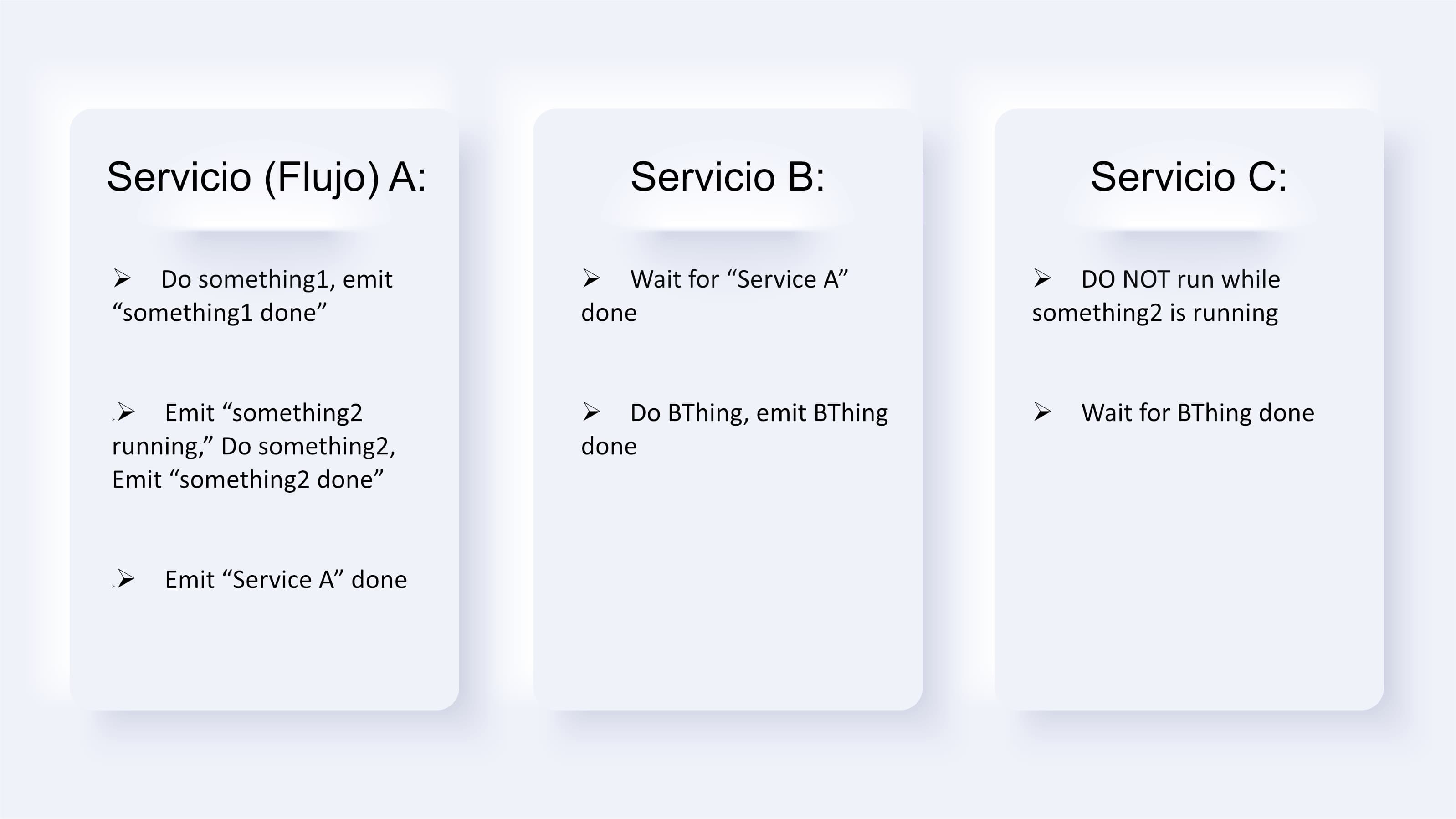
- Piense en microservicios
Evite los monolitos. Esto se aplica tanto a los flujos de trabajo como a las aplicaciones. Identifique componentes o servicios funcionales. Use un enfoque "similar a una API" para los componentes del flujo de trabajo, para que sea fácil conectarlos, reutilizarlos y combinarlos, así:
- Orqueste desde cualquier lugar
La adopción de los servicios de nube crece día tras día, permitiendo a las organizaciones elaborar servicios híbridos a precios ajustados usando tecnologías avanzadas, sin embargo, esta ventaja puede convertirse en una complejidad al momento de administrar múltiples nubes, la seguridad entre sus conexiones y la trazabilidad para mantener la continuidad de los procesos.
Para simplificar este seguimiento, las empresas están buscando tener una capa de consolidación y automatización que ofrezca un único punto de control sobre todos los servicios corporativos, sin importar si corren en tierra o en cualquier nube.
- Secuencialidad del proceso
La secuencialidad de los hechos se cita con frecuencia como un requisito importante para realizar el análisis de problemas complejos. Esta secuencialidad de procesos es igual de importante y un requisito obligatorio para un seguimiento efectivo de los datos. Si no contamos con la capacidad de rastrear la secuencia de procesamiento que llevó un proceso a un punto específico, es muy difícil analizar los problemas. La necesidad aparece cuando se presenta un problema durante la ejecución de procesos automatizados y debemos resolverlos de forma rápida y contundente.
- Vuelva el trabajo visible
Las relaciones de los procesos automatizados deben ser visibles. ¿Alguna vez se encontró con una situación en la que todo parecía perfectamente normal, pero nada funcionaba? Allí es cuando la visualización es particularmente valiosa.
Tener una idea clara de todos los procesos e identificar gráficamente que una acción no se activó porque el evento previo nunca terminó, puede ser extremadamente valioso en la resolución de problemas y en la definición de procesos de auto-remediación (Self-Healing).
- Configure Acuerdos de Niveles de Servicios
La mejor manera de definir una “no acción” como un error es precisando una "expectativa de ejecución", comúnmente llamada nivel de servicio. En su forma más básica, un acuerdo de nivel de servicio – ANS (o SLA por sus siglas en inglés) no cumplido, se identifica como un error.
Por ejemplo, si esperamos que un archivo llegue entre las 4:00 p. m. y las 6:00 p. m. pero se tarda aproximadamente 15 minutos en limpiar y enriquecer al archivo más otros 30 minutos en procesarlo, entonces podemos configurar un ANS de límite de finalización del proceso para las 6:45 p. m. Si para ese momento el procesamiento aún no ha comenzado o el flujo no se ha completado, podremos disparar una alarma de error en el servicio.
Un enfoque más sofisticado es utilizar datos de tendencias para predecir un error de ANS lo antes posible. Sabemos que el paso de limpieza dura aproximadamente 15 minutos porque recopilamos el tiempo de ejecución real de las últimas "n" ocurrencias. Lo mismo para el paso de procesamiento, si el paso de limpieza no ha terminado a las 6:15, o el paso de procesamiento no ha comenzado a las 6:15, sabemos que llegaremos tarde. Podemos generar alertas y notificaciones tan pronto como lo sepamos, de modo que tengamos el máximo tiempo para reaccionar y posiblemente rectificar el problema.
Una mejora final es proporcionar "tiempo de holgura" para informar a los humanos cuánto tiempo queda para corregir el rumbo. En el escenario anterior, si el paso de limpieza no comienza a tiempo, a las 6:00 p. m., tenemos 45 minutos disponibles para solucionar el problema antes de que se incumpla el tiempo acordado para el servicio.
- Categorice
A medida que convierte los "microservicios" de su flujo de trabajo y las tareas de conexión en flujos de procesos, asegúrese de etiquetar objetos con valores significativos que lo ayudarán a identificar relaciones, propiedades y otros atributos que son importantes para su organización.
- Use convenciones de codificación
Imagine crear una API para la autorización de tarjetas de crédito y llamarla "Validar". Si bien tiene sentido para usted, puede ser demasiado vago. Considere calificadores que tengan más significado, como "Validación de tarjeta de crédito".
Es importante tener esto en cuenta al nombrar los flujos de trabajo. Puede ser genial llamar a un flujo de trabajo "MyDataPipeLine" cuando está experimentando en su propia máquina, pero eso se vuelve bastante confuso incluso para usted si se suman las docenas de ejecuciones en un entorno de múltiples usuarios.
- Piense en los demás
Es posible que se encuentre en la posición relativamente extraña de ser la única persona que ejecuta su propio proceso o servicio. Lo más probable es que ese no sea el caso, pero incluso si lo es, no querrá tener que volver a recordar qué hace cada flujo cada vez que necesite modificarlo, mejorarlo o analizar un problema.
Incluya comentarios o descripciones sobre sus flujos de trabajo o, si es realmente un proceso complicado, agregue alguna documentación y recuerde actualizarlos en la medida que se enriquecen sus procesos y servicios.
- Trazabilidad sobre la ejecución
Las mentes curiosas quieren saberlo todo: ¿quién creó el flujo de trabajo?, ¿quién lo ejecutó?, ¿se detuvo o lo pausaron?, ¿quién lo hizo y por qué?, ¿se ejecutó con éxito o falló? Si es así, ¿cuándo y por qué?, ¿cómo se arregló?, entre otras tantas preguntas. Básicamente, cuando se trata de procesos para aplicaciones importantes, nunca se tiene demasiada información. Asegúrese de que su plataforma pueda recopilar todo lo que necesite.
- Analice las estadísticas de ejecución
Contar con datos sobre los procesos ejecutados le permitirá a la organización identificar aspectos como los errores más comunes, el proceso que más se retrasa o el tiempo del día en donde no se están aprovechando los recursos de cómputo. La analítica de datos es cada vez más importante y debemos usarla también para la mejora de nuestros servicios de negocio.
- Aproveche la auto-remediación inteligente
La experiencia de ejecutar múltiples veces un servicio resulta en una recopilación de experiencias sobre los errores de ejecución ocurridos en el pasado, que se recopilan en una base de conocimiento o, en el peor de los casos, en la memoria del operador.
Para identificar códigos de error en cada uno de los pasos y que se configure la solución automática en caso de recibir dicho error ¿qué tal si extendemos ese conocimiento al flujo orquestado? Esto nos permitiría contar con procesos cada vez más autónomos y tener una vida más tranquila.
Artículo original de Joe Goldberg “12 Best Practices for Implementing Application Workflow Orchestration”. Traducido y complementado por Rolando A. Barajas Moreno





